Hypercharging Oracle Data Loading

Is there any limit to the speed of Oracle? With Oracle announcing a new record one million transactions per minute, many believe that there is nothing that Oracle cannot do.
However, what if we have a requirement for a system that must accept high-volume data loads into a single table:
- 500,000 rows per second
- 50 megabytes per second
Is this possible? Using the right tricks you can make Oracle load data at unbelievable speed. However, special knowledge and tricks are required.Oracle provides us with many choices for online data loading:
- SQL insert and merge statements
- PL/SQL bulk loads using the forall operator
If we can load in batch mode, we also have more options:
- SQL*Loader
- Oracle Data Pump
- Oracle import utility
However there are vast differences in load speed (Figure 1).
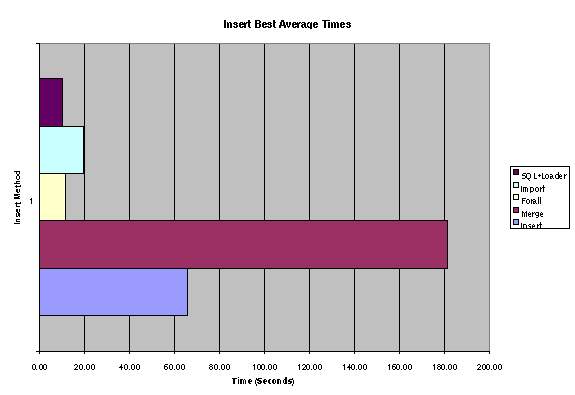 Figure 1: Sample data load speeds
Figure 1: Sample data load speeds
Batch Data Loading
If you are loading your data from flat files there are many products and Oracle tools to improve your load speed:
Oracle Data load tools:
- Oracle10g Data Pump (available January 2004) - With Data Pump Import, a single stream of data load is about 15-45 times faster than original Import. This is because original Import uses only conventional mode inserts, whereas Data Pump Import uses the direct path method of loading.
Oracle SQL*Loader - Oracle SQL*Loader has dozens of options including direct-path loads, unrecoverable, etc and get super-fast loads. Here are tips for getting high-speed loads with SQL*Loader.
Oracle import Utility - Oracle has numerous options to improve data load speed with its import utility.
Third-party Data load tools:
- BMC Fast Import for Oracle - Claims to be 2 to 5x faster than Oracle import utility.
CoSORT FAst extraCT (FACT) for Oracle - Claims to get Bulk loads up to 90% faster when CoSORT pre-sorts the load file on the table's index key. This also improves clustering_factor and improves run-time SQL access speeds by reducing logical I/O.
Online Data Loading
Don't use standard SQL insets as they are far slower than other approaches. If you must use SQL inserts, make sure to use the APPEND hint to bypass the freelists and raise the high-water mark for the table. You are way better off using PL/SQL with the bulk insert features (up to 100x faster).
Other things to ensure:
- Use parallel DML - Parallelize the data loads according to the number of processors and disk layout. Try to saturate your processors with parallel processes.
Disable constraints and indexes ? Disable RI during load and re-enable (in parallel) following the load.
Tune object parms - Use multiple freelists or freelist groups for target tables. Avoid using bitmap freelists ASS management (automatic segment space management) for super high-volume loads.
Pre-sort the data in index key order - This will make subsequent SQL run far faster for index range scans.
Use RAM Disk - Place undo tablespace and online redo logs on Solid-state disk (RAM SAN)
Use SAME RAID - Avoid RAID5 and use Oracle Stripe and Mirror Everywhere approach (RAID 0+1, RAID10). However, this doesn't mean one large array smeared with everything, you will see performance gains from separating temp, data and index, redo and undo segments onto separate RAID areas.
Use a small db_cache_size - This will minimize DBWR work. In Oracle9i you can use the alter system set db_cache_size command to temporarily reduce the data buffer cache size.
Watch your commit frequency - Too frequent checkpoints can be a performance issue. To few commits can cause undo segment problems.
Use a large blocksize - Data loads onto 32k blocksizes will run far faster because Oracle will be able to insert more rows into an empty block before a write.
Here is a small benchmark showing the performance of loads into a larger blocksize:
alter system set db_2k_cache_size=64m scope=spfile; alter system set db_16k_cache_size=64m scope=spfile; startup force create tablespace twok blocksize 2k; <-- using ASM defaults to 100m create tablespace sixteenk blocksize 16k; create table load2k tablespace twok as select * from dba_objects; < creates 8k rows drop table load2k; <- first create was to preload buffersset timing on;
create table load2k tablespace twok as select * from dba_objects;
create table load16k tablespace sixteenk as select * from dba_objects;
For a larger sample, I re-issued the create processes with:
select * from dba_source; -- (80k rows)
Even with this super-tiny sample on Linux using Oracle10g with ASM the results where impressive:
2k 16k blksze blksze 8k table size 4.33 secs 4.16 secs 80k table size 8.74 secs 8.31 secs
Driving your server
It is critical to take STATSPACK reports during data loading, paying special attention to the top-5 wait events.
- I/O-bound - Move to faster media (SSD), especially for undo and redo files.
CPU-bound - Add more processors and increase degree of parallel DML
Network-bound - Move data loading onto the save server as the Oracle instance
Using these techniques you can achieve blistering data load speeds for multi-terabyte Oracle databases.
- Donald K. Burleson's blog
- Log in to post comments
Comments
Its really good document on import to improve performance but I am in confuse regarding following parameter setting.
Link Name
http://www.orafaq.com/articles/archives/000020.htm
Topic Heading
On line Dataload
( Size your log_buffer properly - If you have waits associated to log_buffer size "db log sync wait", try increasing to 10m. )
LGWR will clean up buffers if log_buffer 1/3 full, 1mb log_buffer full or commit occurs. If we change log_buffer to 10mb will it helpful to improve performance.
Thanx
Umakant
There should be some tips & techniques addressed while considering to resolve a performance isuue rather than optimizing tool.Buying a optimizing tool pays a more money than usual.
Nice article , but for this statement.
"
- At each commit, the DBWR process will try to write all dirty blocks to disk, performing an expensive full-scan of the RAM data buffer (db_cache_size). To minimize DBWR work, commit as infrequently as possible. "
is incorrect !
DBWR DOES NOT try to write ALL dirty blocks to the disk on every commit and it does not perform a full-scan of the buffer cache. It certainly causes LGWR to flush the log buffers to redolog files on the disk.
Even in case where DBWR has to scan the recently updated blocks to perform a commit cleanout,its restricted to 10% of the data buffer cache and other restrictions.
Frequent commits are certainly bad from performance perspective,but mostly becos it involves undo segment header updates(transaction slot with commit scn, undo block address updates),writing the undo change into redo stream along with the actual data block/index block changes, physically writing these redo buffers into the logfiles,sending out a commit confirmation and performing any commit cleanouts.
-Thiru Vadivelu
Sr.Oracle DBA/Consultant
Delaware,USA